RAG 应用
RAG 应用
1、RAG 应用前言
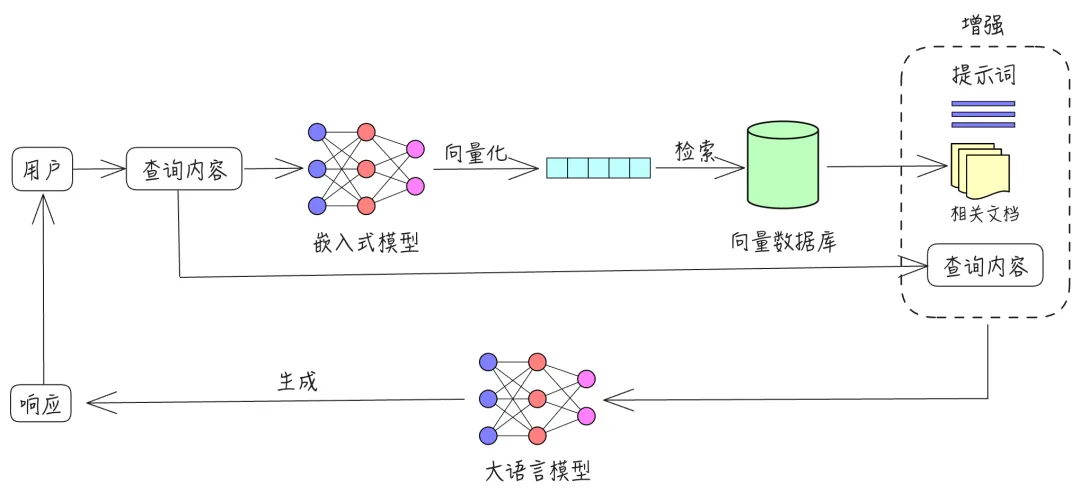
RAG 是 Retrieval-augmented Generation 的简写,指的是检索增强生成。 2020 年,Facebook AI Research(FAIR) 团队发表名为《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》的论文,首次提出了RAG概念,RAG 是当下热门的大模型前沿技术之一。 通过RAG技术,大语言模型在回答问题时,可以从企业知识库中检索最新的相关信息来生成内容,从而提高回答的准确性、关联性和新鲜度,并解决幻觉问题。同时,RAG技术外挂的私有数据不参与大模型训练,保证了企业的数据安全。
2、RAG 的流程和原理
Embedding 嵌入
Embedding
1、什么是 Embedding
Embedding 我们可以简单的理解为:有一种算法(或模型),能够把高纬数据映射到一个低维度的向量空间的过程,这个映射的过程,本质上是一个数据特征提取的过程。 低纬度的向量数据,可以减少数据的复杂性,从而提高模型的训练和推理效率。
2、示例代码
Llm llm = OpenAILlm.of("sk-rts5NF6n*******");
VectorData embeddings = llm.embed(Document.of("some document text"));
System.out.println(Arrays.toString(embeddings.getVector()));VectorStore 向量存储
VectorStore
1、什么是 VectorStore
Agents-Flex 的 Store 指的是向量存储器 VectorStore。 其定义了如下的方法,用于对向量数据进行增删改查:
store(List<T> documents, StoreOptions options)用于存储向量数据delete(Collection<String> ids, StoreOptions options)用于删除向量数据update(List<T> documents, StoreOptions options)用于更新向量数据search(SearchWrapper wrapper, StoreOptions options)用于查询(召回)向量数据
目前,在 Agents-Flex 中,已经完成了以下向量数据库的适配:
- 阿里云向量检索服务:https://help.aliyun.com/document_detail/2510317.html
- 腾讯云向量数据库:https://cloud.tencent.com/document/product/1709/98666
- Milvus 向量数据库:https://milvus.io
以下更多的向量数据库适配正在完善中:
agents-flex-store-chroma:chroma 向量数据库agents-flex-store-elasticsearch:elasticsearch 向量存储agents-flex-store-opensearch:opensearch 向量存储agents-flex-store-redis:redis 向量数据存储
2、示例代码
AliyunVectorStoreConfig storeConfig = new AliyunVectorStoreConfig();
//设置阿里云向量数据检索服务的相关配置
storeConfig.setApiKey("...");
storeConfig.setEndpoint("...");
storeConfig.setDatabase("...");
DocumentStore store = new AliyunVectorStore(storeConfig);
//创建 Embedding 模型,
EmbeddingModel llm = new OpenAILlm.of("sk-rts5NF6n*******");
//为 store 配置 Embedding 模型
store.setEmbeddingModel(llm);完成以上的设置,我们就可以愉快的使用 store 来对向量数据进行 增删改查 了。
新增数据:
Document document = new Document();
document.setId(100);
document.setContent("文档的文本数据...巴拉巴拉");
store.store(document);更新数据:
Document document = new Document();
document.setId(100);
document.setContent("新的文档数据...巴拉巴拉");
store.update(document);删除数据:
store.delete(100);数据召回
SearchWrapper wrapper = new SearchWrapper();
wrapper.setText("关键字或者提示词");
List<Document> result = store.search(wrapper);3、SearchWrapper
目前,在向量数据库领域中,并不存在一个类似 SQL 的语言,来统一数据库查询。每一家的向量数据库都是提供了不同的 API 或者独特的查询语言。
Agents-Flex 为了消灭各个向量数据库的查询差异,因而开发了 SearchWrapper,用于对各个向量数据库的统一适配。
SearchWrapper 支持生成 Filter Expression(过滤表达式,类似为 SQL 的 where 部分)用于对向量数据库的进一步过滤。
@Test
public void testSearchWrapper() {
SearchWrapper rw = new SearchWrapper();
rw.eq("akey", "avalue").eq(Connector.OR, "bkey", "bvalue").group(rw1 -> {
rw1.eq("ckey", "avalue").in(Connector.AND_NOT, "dkey", "bvalue");
}).eq("a", "b");
String expr = "akey = \"avalue\" " +
"OR bkey = \"bvalue\" " +
"AND (ckey = \"avalue\" AND NOT dkey IN \"bvalue\") " +
"AND a = \"b\"";
Assert.assertEquals(expr, rw.toFilterExpression());
}Document 文档
Document 文档
1、Document 介绍
在 Agents-Flex 中,Document 是一个带有向量数据的文档对象。其定义如下
public class Document extends VectorData {
/**
* 文档 ID
*/
private Object id;
/**
* 文档内容
*/
private String content;
}- id: 文档 id
- content: 文档内容
由于其带有向量数据,因此可以被存储在向量数据库(VectorStore)中。
在文档模块中,除了 Document 本身以外,还提供了如下几种组件:
- DocumentLoader: 文档加载器,用于从不同的地方加载(读取)内容(比如本地磁盘、数据库、网站等)文档内容。
- DocumentParser: 文档解析器,用于对不同类型的文档进行解析,最终得到 Document 对象,比如解析 word、pdf、html 等等。
- DocumentSplitter: 文档分割器,用于对大文档进行分割,生成多个小文档,方便 Embedding 计算以及向量数据库存储。
2、DocumentLoader 文档加载器
在 Agents-Flex 中,提供了如下两种文档加载器(未来会提供更多的类型):
- FileDocumentLoader: 文件文档加载器
- HttpDocumentLoader: HTTP 文档加载器
未来我们会新增更多类型的文档加载器,比如数据库加载、FTP 加载。或者特定领域的加载器,比如微信公众号加载器等。用户也可以实现自己的加载,欢迎大家参与和分享。
3、DocumentParser 文档解析器
文档解析器用于对不同类型的文档进行解析,最终得到 Document 对象,Agents-Flex 已内置的文档解析器如下:
- PdfBoxDocumentParser: 对 PDF 解析
- PoiDocumentParser: 对 Word 文档进行解析
4、DocumentSplitter 文档分割器
文档分割器是用来对大文档进行分割为多个小文档的场景,不同的分割器可以用于不同的分割场景。目前 Agents-Flex 提供的文档分割器如下:
- SimpleDocumentSplitter: 可以通过正则表达式进行分割
- MarkdownDocumentSplitter: 对 Markdown 内容进行分割
- ParagraphDocumentSplitter: 通过段落进行分割
向量数据库配置样例
Redis向量数据库
1、部署Redis向量数据库
Redis向量数据库是包含redisSearch功能组件的Redis,这里使用docker版实现快速部署
docker run --name redis_stack -e REDIS_ARGS="--requirepass Test2025L" -p 6379:6379 -d --restart=always redis/redis-stack-server:latest2、知识库页面配置
向量数据库类型选择Redis,向量数据库配置中填写uri = redis://:Test2025L@127.0.0.1:6379,向量数据库集合中填写知识库英文缩写如:redisKnowledge,Embedding 模型中选择一个模型(大模型菜单中能力是Embedding的模型) 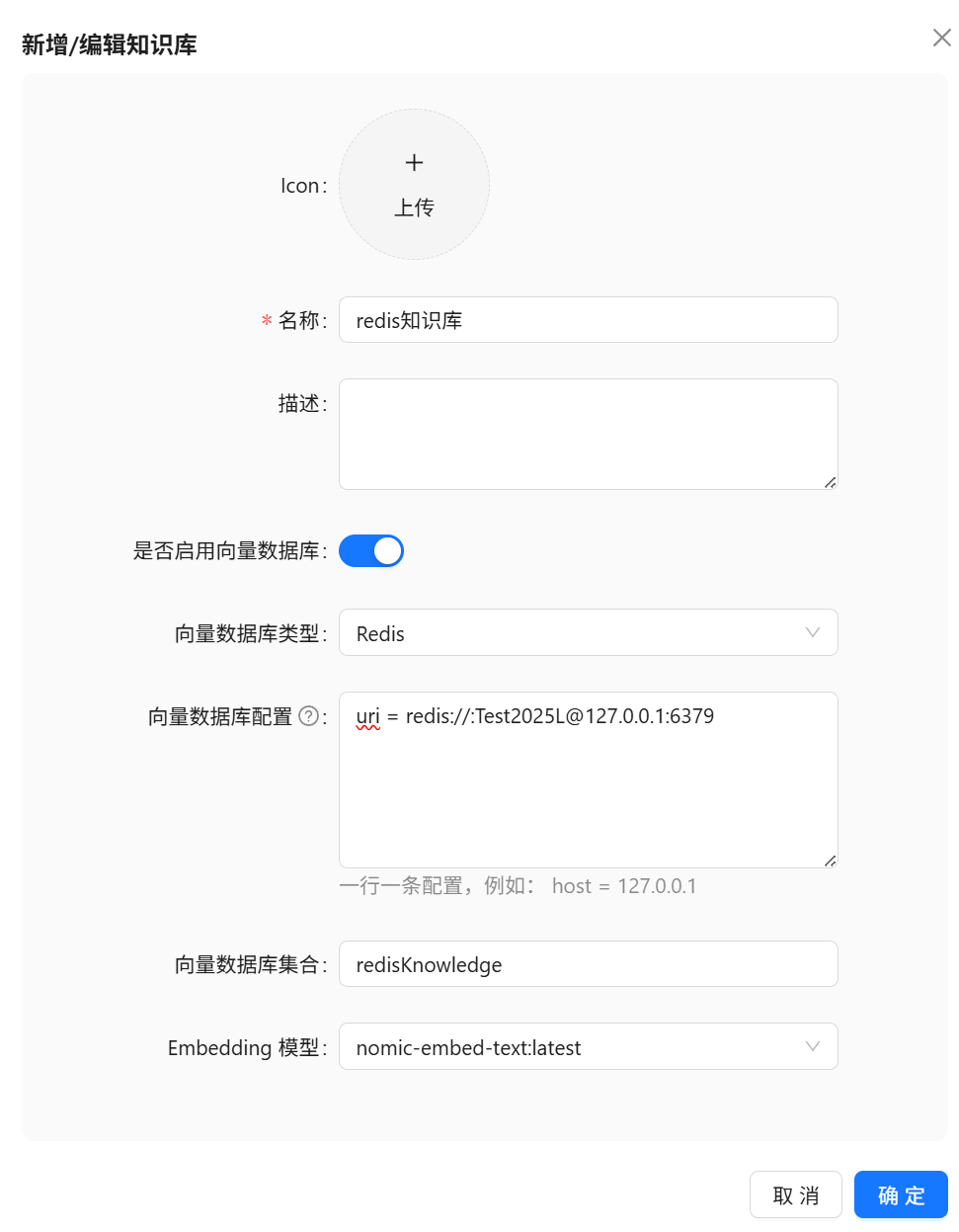
扩展:向量数据库配置中还可以增加storePrefix、defaultCollectionName 等配置,配置了defaultCollectionName 时新增/编辑知识库页面中的“向量数据库集合”可以为空。
storePrefix = docs:
defaultCollectionName = documents3、文件导入
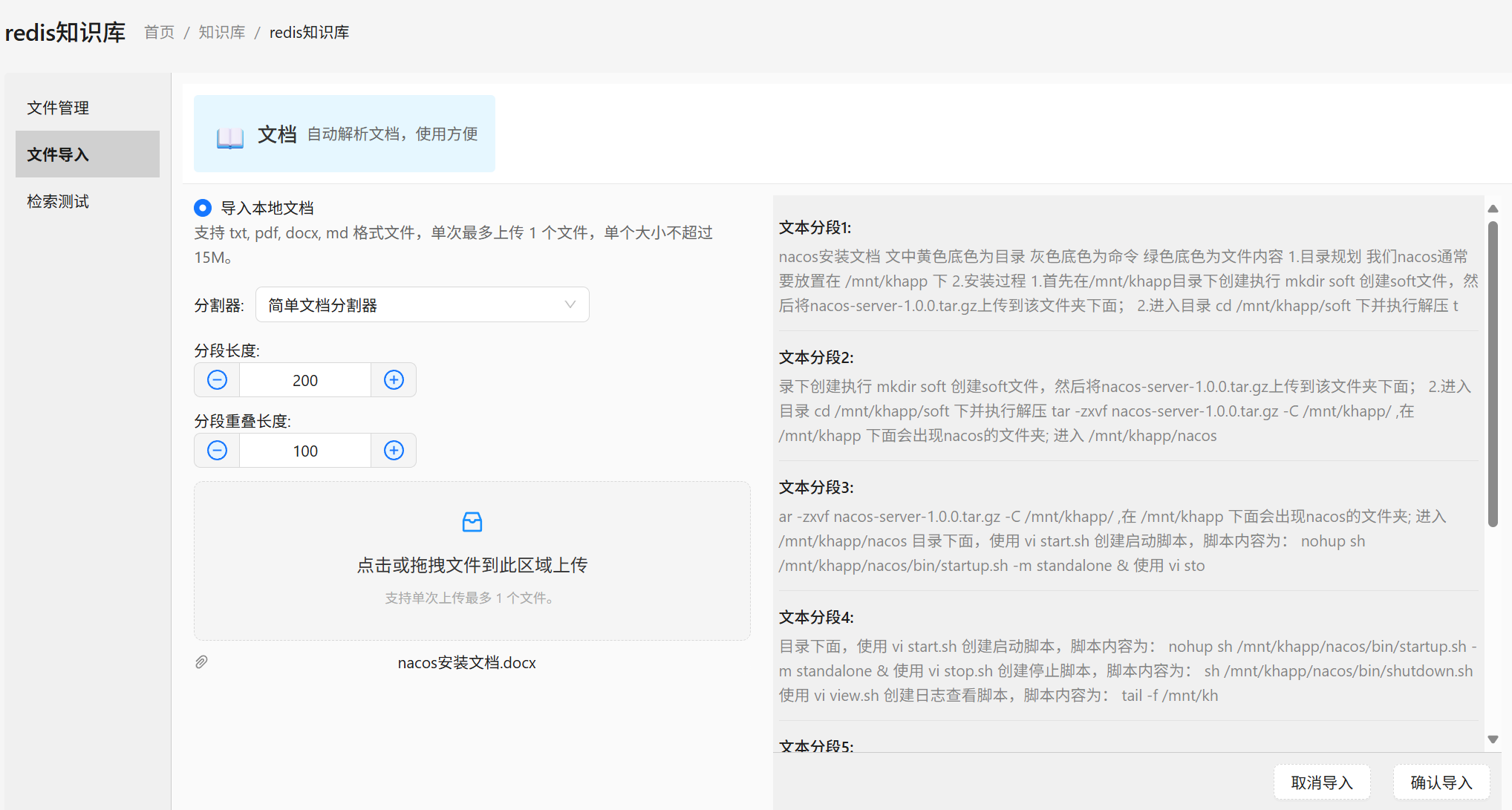
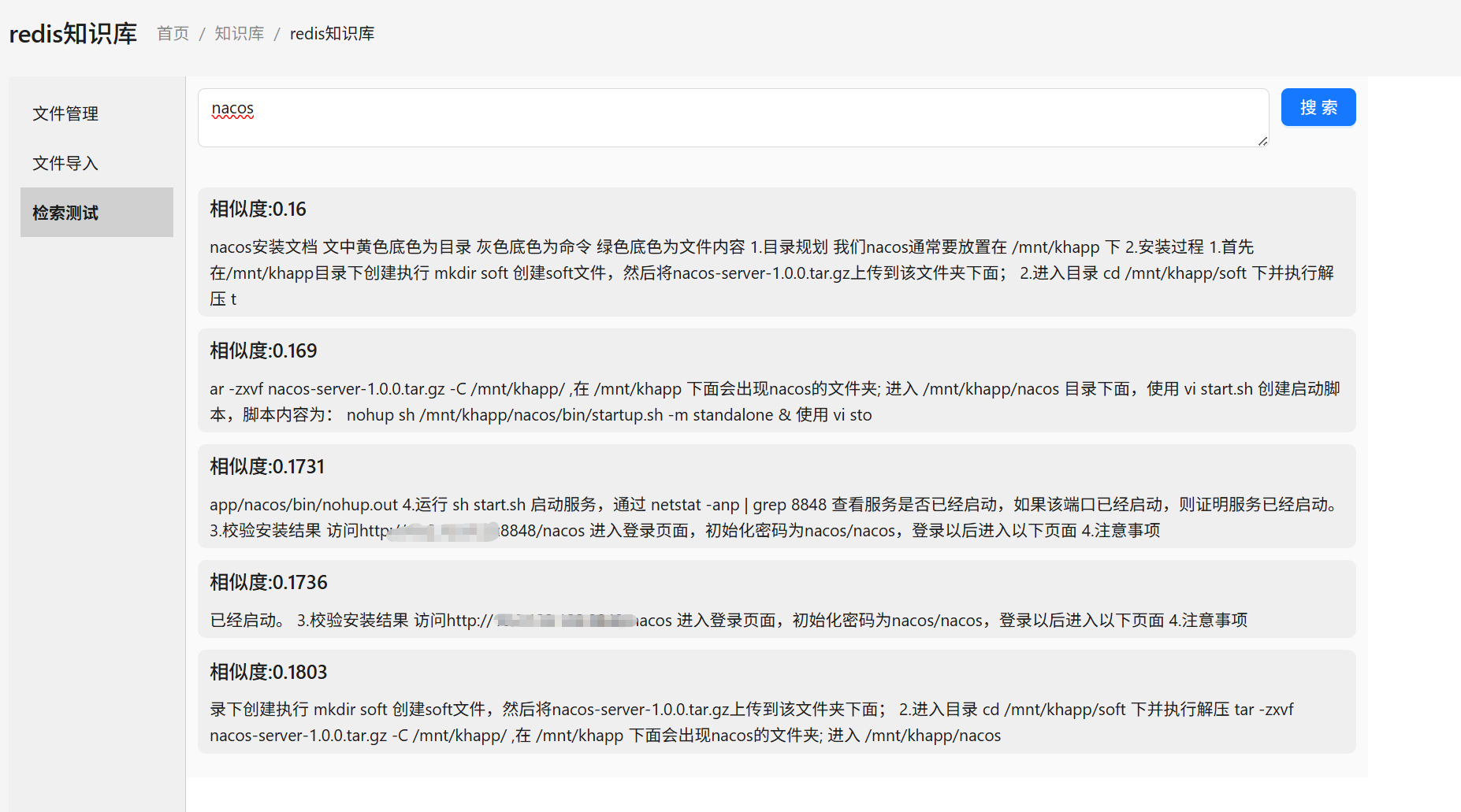
四、检索测试
Milvus 向量数据库
1、安装 DockerDesktop
这里介绍windows使用 dockerDesktop 部署 Milvus 向量数据库
- 安装dockerDesktop , 点开连接,直接点击Download for Windows即可下载 https://docs.docker.com/desktop/setup/install/windows-install/
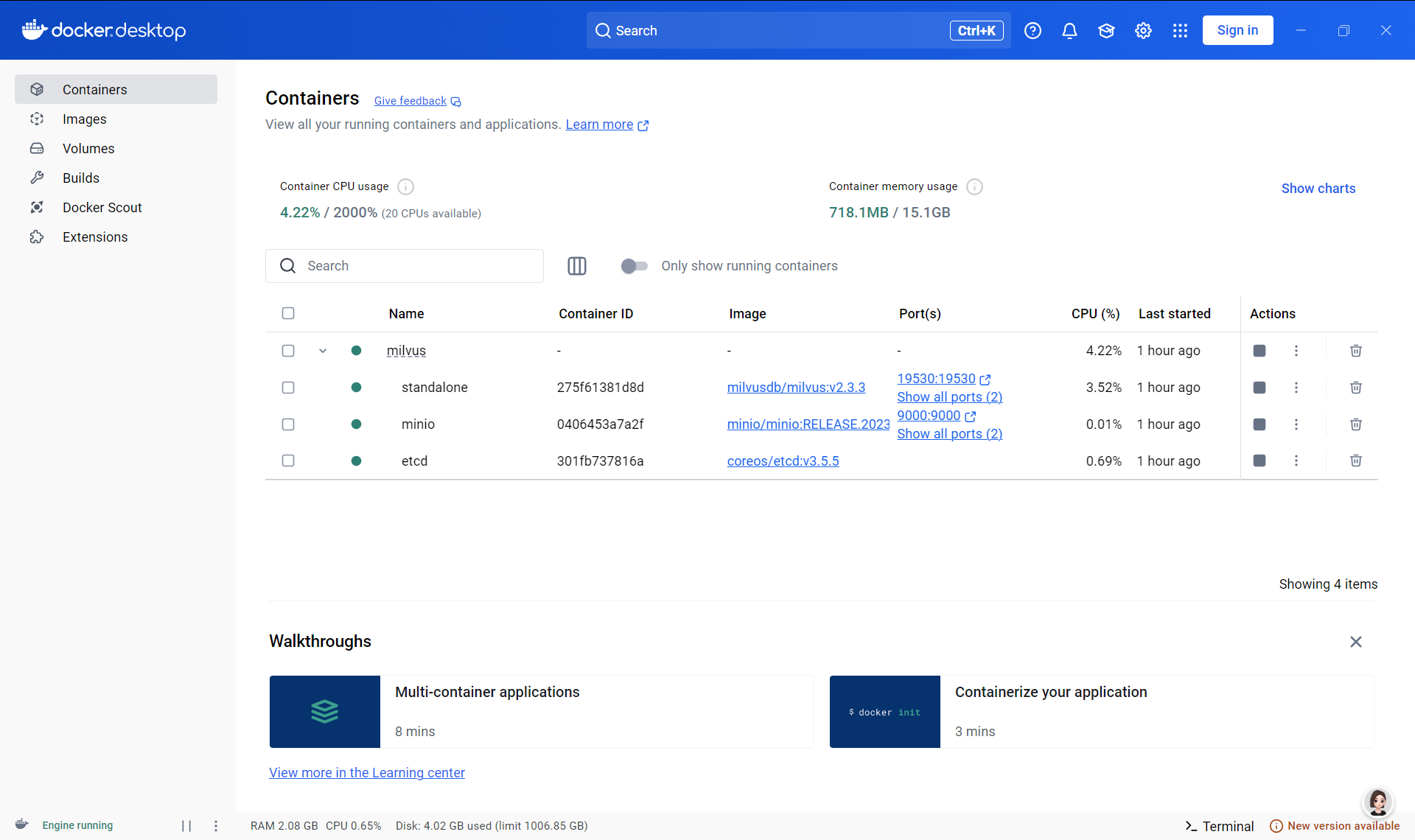
- 下载好了安装,直接安装即可。安装完了打开Docker可视化页面。 如果页面为以下内容则表示成功(如果页面空白,则需要设置网络,保证能访问docker镜像仓库):
验证是否安装成功
#查看docker版本
docker --version
#查看docker-compose版本
docker-compose --version2、部署 Milvus 向量数据库
- Milvus下载 从链接中: 下载选择自己所需的版本即可,这里我选择的是最新版本milvus-2.5.11 https://github.com/milvus-io/milvus/releases/tag/v2.5.11
在你的本地建立一个milvus文件夹,将下载好的文件拷贝至刚刚创建的milvus下,并改名为:docker-compose.yml。记得一定要改名,不然会报错。
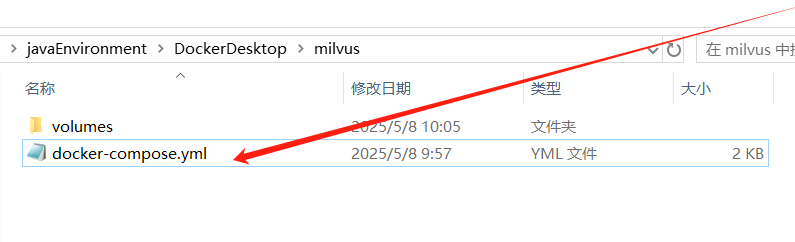
- Milvus启动与验证 打开cmd命令行,进入docker-compose.yml文件所在的目录。 输入命令: docker compose up -d,这里记得设置自己的网络,不然加载不了。

3、Milvus 图形化界面attu的安装
- attu下载 大家可以点击下载attu选择自己所需的版本,我使用的为最新版本Release v2.4.6
https://github.com/zilliztech/attu/releases/tag/v2.5.8
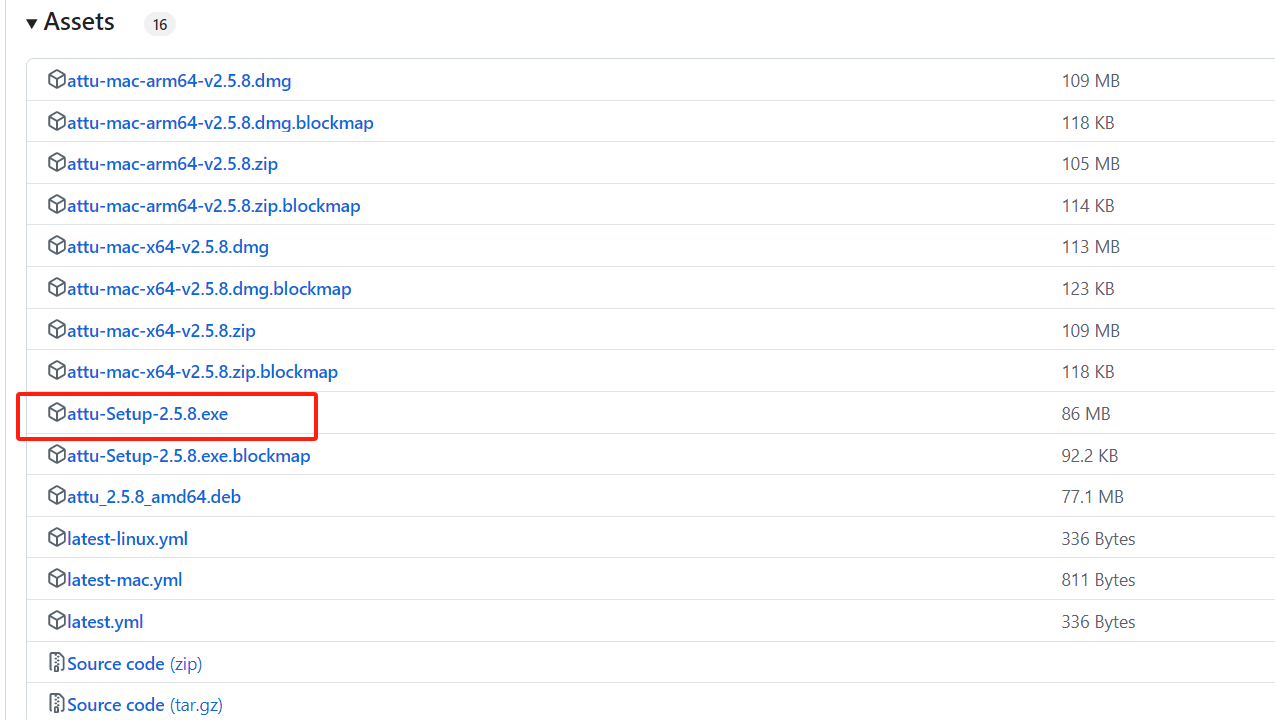
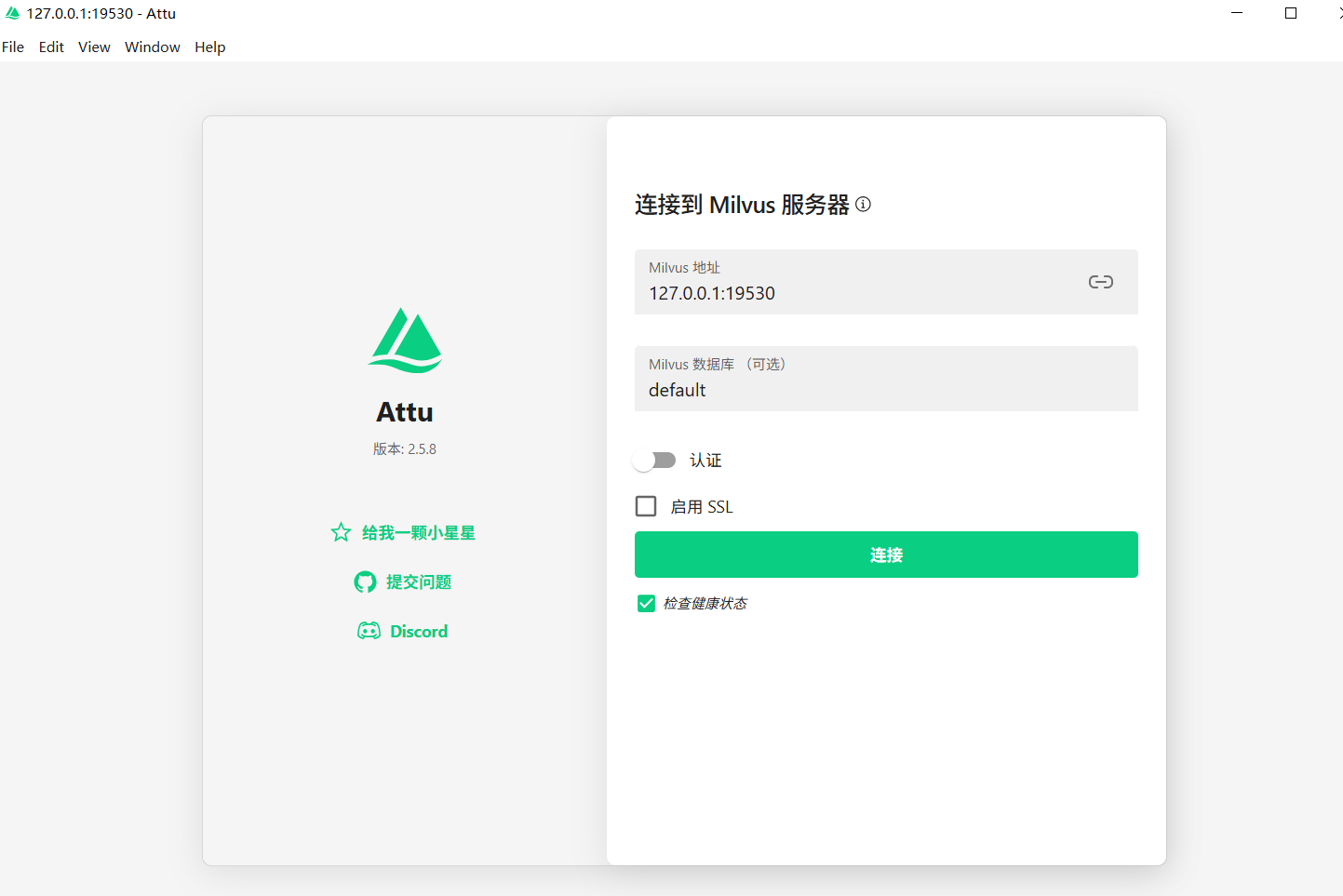
- attu安装 下载安装文件后,直接安装就行。安装后打开的页面是这样:
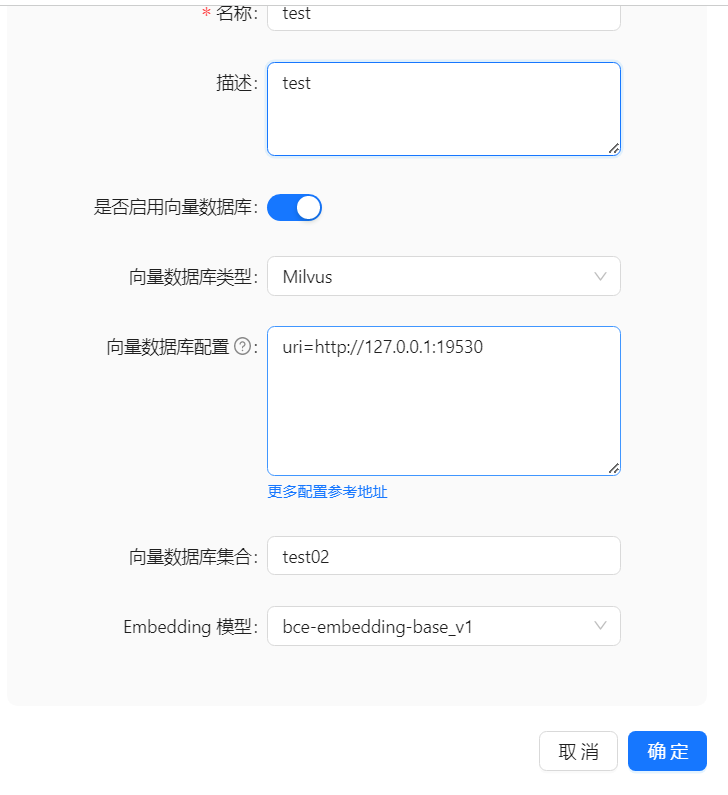
4、Milvus 向量数据库配置
Milvus 向量数据库配置
- 以下为未设置密码的配置样例:
- 以下为设置了密码的配置样例:
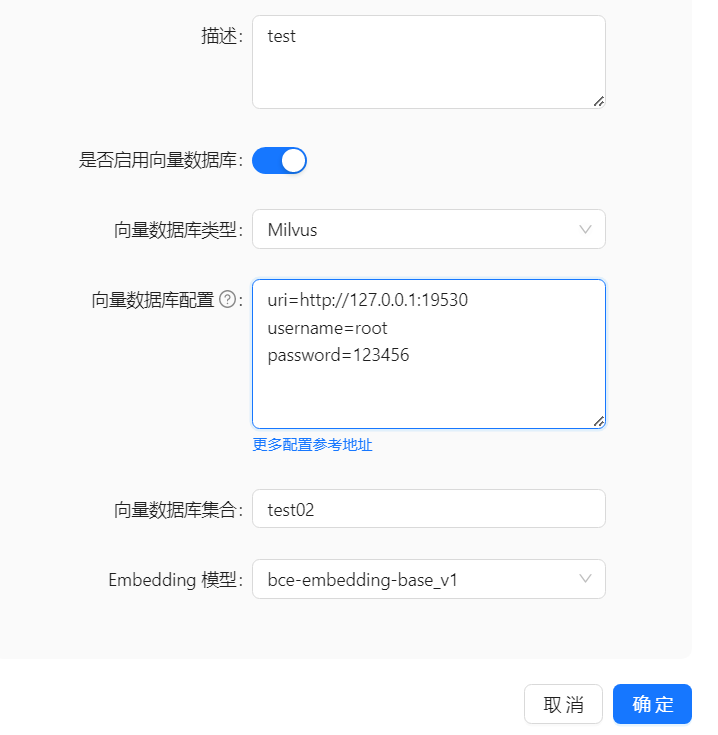
此外 Milvus 还支持更多配置参数
databaseName = "default" 数据库集合名称,默认为default
token :使用token认证,默认为空,为空则不使用token认证
Elasticsearch 向量数据库
1、 Elasticsearch 知识库配置样例
如果没有设置账号和密码,不用添加账号和密码的配置 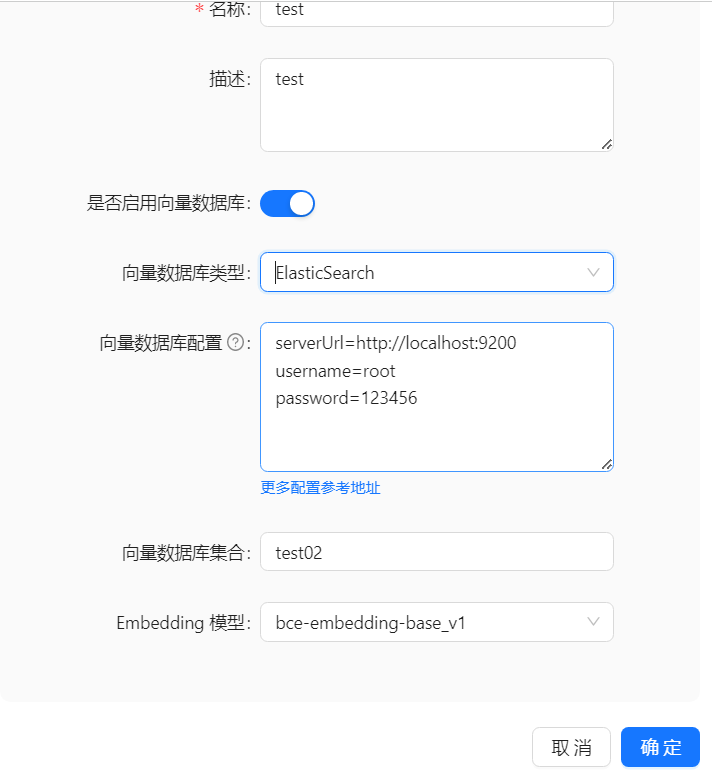
此外 Elasticsearch 还支持更多配置参数 apiKey :使用apiKey认证,默认为空,为空则不使用apiKey认证
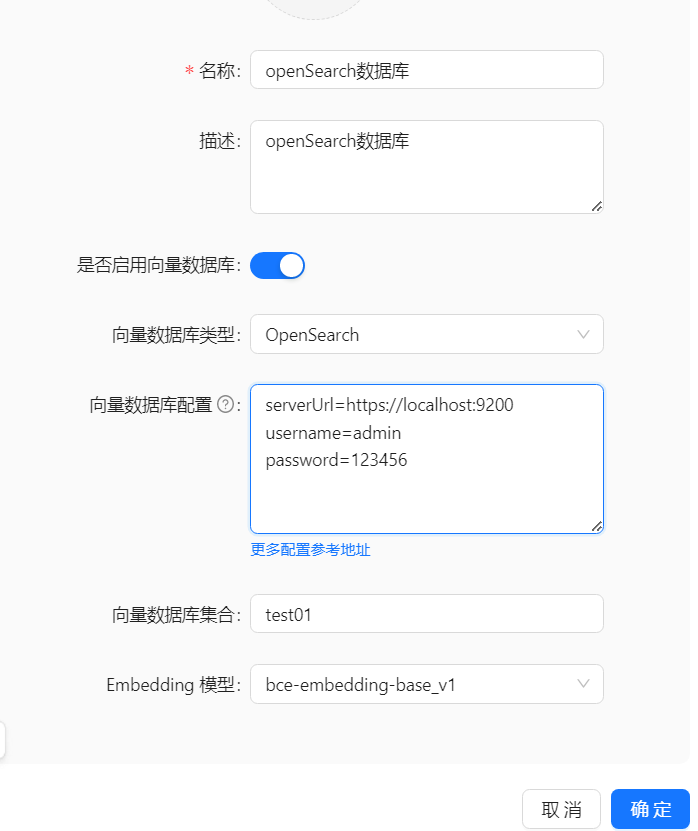
OpenSearch 向量数据库
1、安装OpenSearch
docker 安装参考地址
docker 使用如下如下命令一键设置密码并安装
docker run -d -p 9200:9200 -p 9600:9600 -e "discovery.type=single-node" -e "OPENSEARCH_INITIAL_ADMIN_PASSWORD=yourPassword" opensearchproject/opensearch:2.19.1浏览器向 9200 端口发送请求。默认用户名为 admin ,密码为您设置的密码。
出现以下内容则表示成功
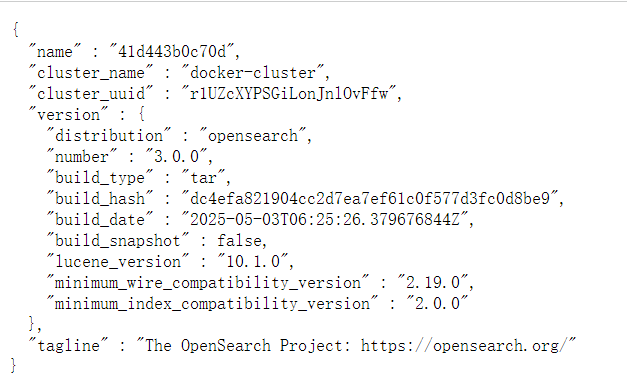
2、OpenSearch 知识库配置样例